在科技巨頭紛紛布局人工智能領(lǐng)域的浪潮中,小米公司近期宣布了一項(xiàng)重大進(jìn)展,正式推出了其首個專注于提升模型推理能力的大型語言模型——Xiaomi MiMo,并且決定將其開源,以供全球開發(fā)者共同研究和使用。
據(jù)小米方面介紹,MiMo模型的誕生,源于對當(dāng)前大模型技術(shù)瓶頸的深刻洞察以及對提升模型推理能力的迫切需求。該模型旨在通過技術(shù)創(chuàng)新,打破現(xiàn)有預(yù)訓(xùn)練模型的局限性,進(jìn)一步激發(fā)AI在復(fù)雜邏輯推理、數(shù)學(xué)運(yùn)算及代碼生成等高級認(rèn)知任務(wù)上的潛力。
在基準(zhǔn)測試方面,MiMo模型展現(xiàn)出了令人矚目的表現(xiàn)。小米公布的測試數(shù)據(jù)顯示,其7B參數(shù)的MiMo模型在多個衡量模型推理能力的公開基準(zhǔn)測試中,性能超越了同類甚至更大規(guī)模的模型。特別是在AIME 24-25評測集和LiveCodeBench v5評測集上,MiMo的表現(xiàn)不僅超過了OpenAI的閉源推理模型o1-mini,還超越了參數(shù)量高達(dá)32B的阿里開源推理模型QwQ-32B-Preview。
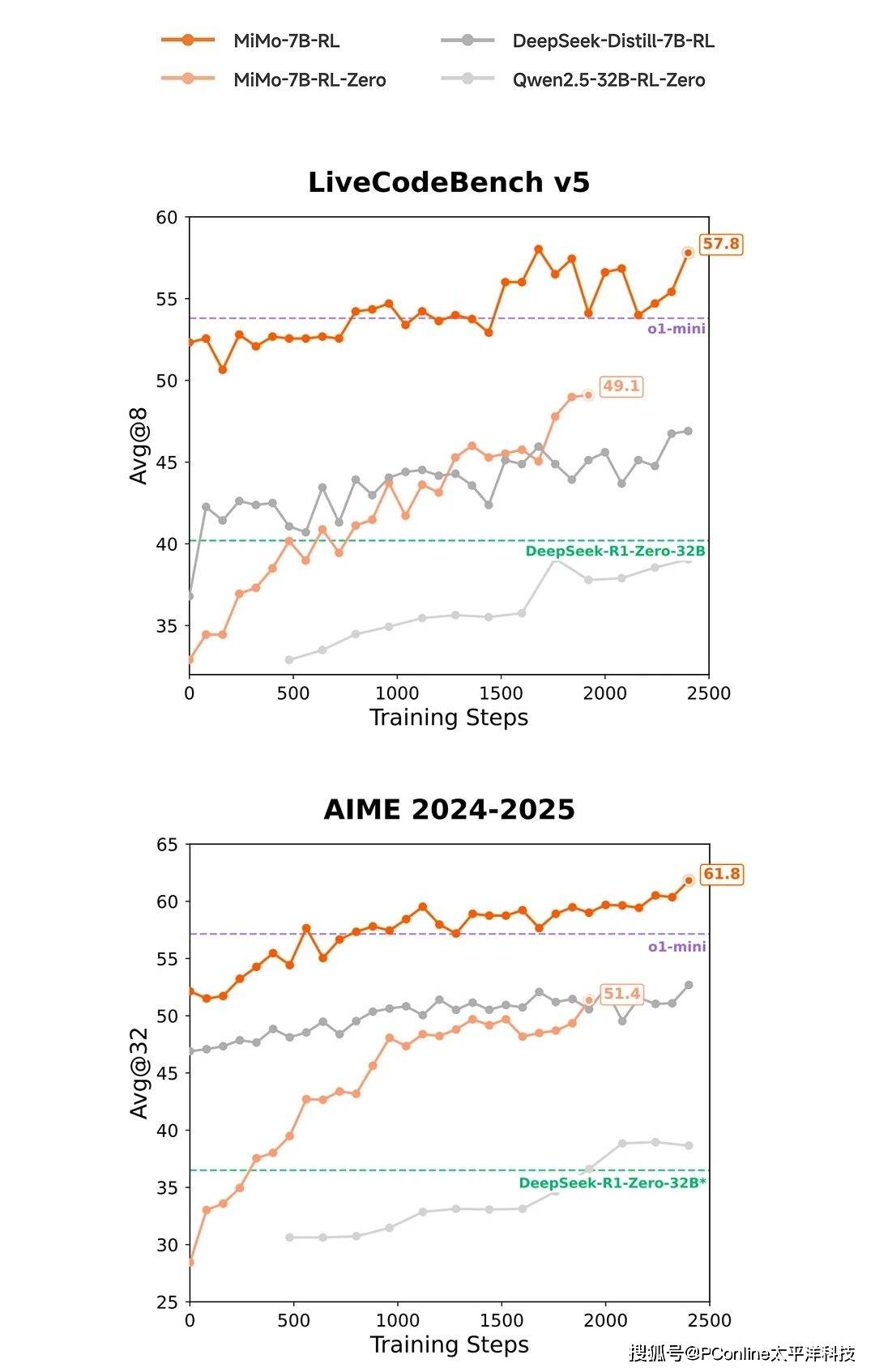
MiMo模型在強(qiáng)化學(xué)習(xí)領(lǐng)域也展現(xiàn)出了顯著的優(yōu)勢。與當(dāng)前業(yè)內(nèi)廣泛用作強(qiáng)化學(xué)習(xí)起始模型的DeepSeek-R1-Distill-7B和Qwen2.5-32B相比,MiMo-7B在數(shù)學(xué)與代碼領(lǐng)域的強(qiáng)化學(xué)習(xí)潛力評估中表現(xiàn)更優(yōu)。這一成果進(jìn)一步證明了MiMo模型在推理效率和效果上的行業(yè)領(lǐng)先地位。
那么,MiMo模型是如何在推理能力上取得如此突破的呢?這得益于小米大模型Core團(tuán)隊(duì)在模型設(shè)計(jì)與訓(xùn)練流程上的多項(xiàng)技術(shù)創(chuàng)新。在預(yù)訓(xùn)練階段,團(tuán)隊(duì)著重挖掘富推理語料,并創(chuàng)新性地合成了約200B tokens的高質(zhì)量推理數(shù)據(jù),采用三階段訓(xùn)練模式,逐步提升難度,累計(jì)訓(xùn)練數(shù)據(jù)量達(dá)到25T tokens。

在后訓(xùn)練階段,小米團(tuán)隊(duì)引入了創(chuàng)新的強(qiáng)化學(xué)習(xí)算法和框架。他們提出了Test Difficulty Driven Reward機(jī)制,旨在緩解困難推理問題中的獎勵稀疏性,并引入Easy Data Re-Sampling策略以提高訓(xùn)練穩(wěn)定性。同時,通過設(shè)計(jì)的Seamless Rollout系統(tǒng),顯著提升了強(qiáng)化學(xué)習(xí)訓(xùn)練效率和驗(yàn)證效率。
為推動人工智能社區(qū)在推理能力方向的共同發(fā)展,小米已將Xiaomi MiMo-7B的四個變體模型全部開源,并托管于HuggingFace平臺。這一舉措使得全球的開發(fā)者和研究人員能夠免費(fèi)獲取并使用這些模型,進(jìn)一步促進(jìn)了人工智能技術(shù)的創(chuàng)新和發(fā)展。
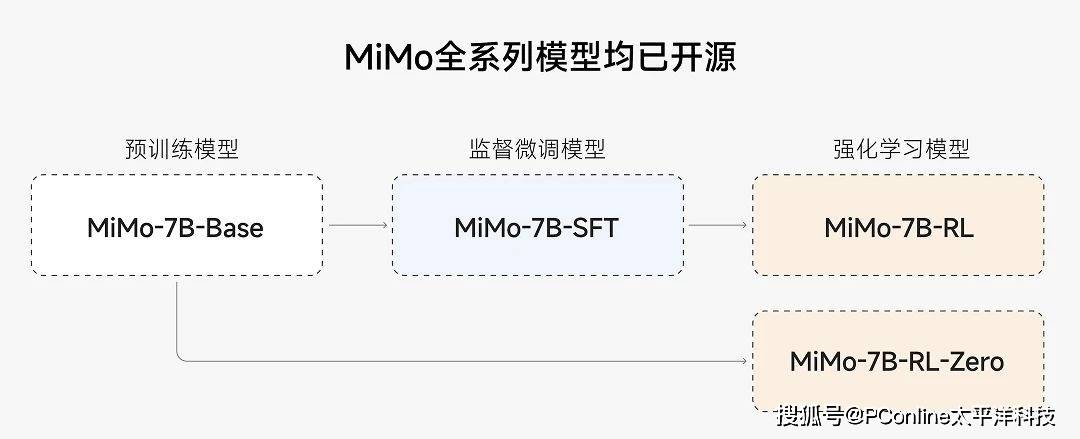
據(jù)了解,Xiaomi MiMo是小米新近成立的「小米大模型Core團(tuán)隊(duì)」的首個重要對外成果。該團(tuán)隊(duì)表示,將繼續(xù)秉持務(wù)實(shí)創(chuàng)新的精神,探索人工智能的前沿領(lǐng)域,致力于通過技術(shù)突破不斷拓展智能的邊界。這一成果不僅展示了小米在人工智能領(lǐng)域的實(shí)力,也為全球開發(fā)者提供了寶貴的研究資源。