在AI領域的一次深夜震撼發布中,阿里巴巴以其迭代速度驚人的千問系列再次吸引了全球目光。這一次,他們推出的Qwen3系列大模型,如同一顆重磅炸彈,直接挑戰了包括DeepSeek在內的頂尖模型,并對Gemini 2.5 Pro構成了強烈沖擊。更引人注目的是,Qwen3不僅是全球首個開源的混合推理模型,還支持多達119種語言和方言,同時兼容MCP協議,一舉奪得了全球開源模型排行榜的桂冠。
這一消息迅速在開發者社區中引爆了熱潮,討論熱度直線飆升。
Qwen3系列此番帶來的“豪華套餐”內容豐富多樣。告別了過去單一參數的大模型時代,Qwen3采取了“組合拳”策略,推出了兩大類型的模型。
首先是MoE(混合專家)模型,包括旗艦級的Qwen3-235B-A22B,總參數超過2350億,但實際激活參數僅為220億多,性能卓越;另一款則是“小鋼炮”Qwen3-30B-A3B,擁有300億總參數和30億激活參數,效率驚人。MoE模型的工作原理類似于聘請了一群專家,只在需要時調用最相關的幾位,從而大大節省了時間和資源。
接著是Dense(密集)模型,共六款,從Qwen3-32B到Qwen3-0.6B,覆蓋了不同規模的算力需求,真正做到了靈活選擇,且每款模型都展現出了極高的“能效比”。
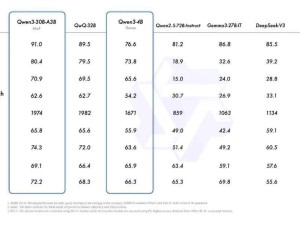
在性能表現上,Qwen3主打“能效比”。旗艦模型Qwen3-235B-A22B在代碼、數學、通用能力等基準測試中均取得了極具競爭力的成績。
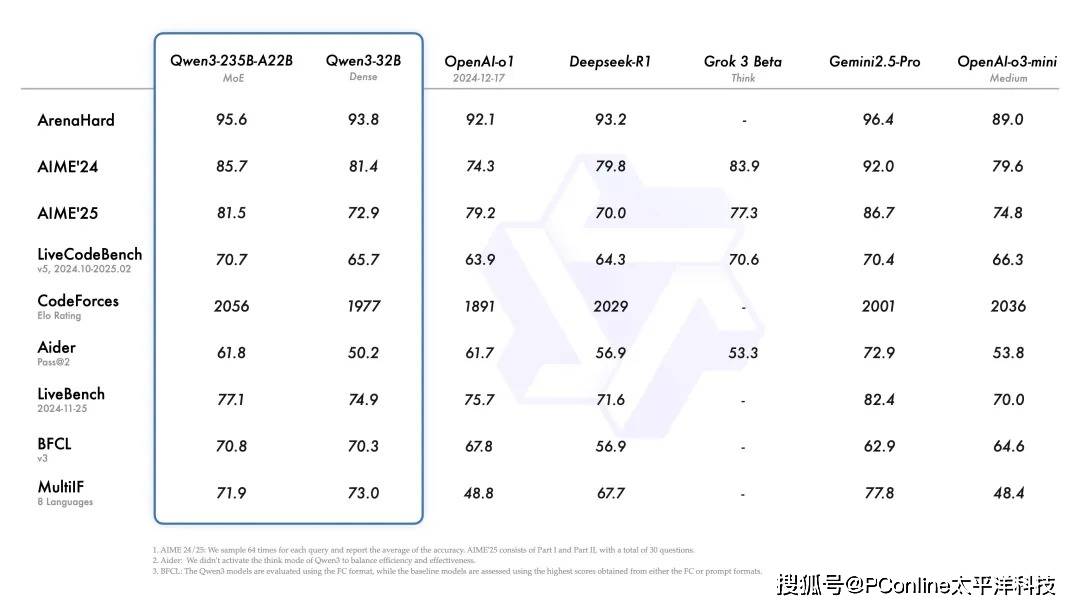
尤為值得一提的是效率的提升,如30B的MoE模型Qwen3-30B-A3B,僅用相當于32B Dense模型10%的激活參數,就實現了更優的性能。即便是小模型Qwen3-4B,也能與上一代Qwen2.5-72B-Instruct相媲美,實現了資源的最優化利用。Qwen3的Dense模型在同等尺寸下,整體性能也超越了參數量更大的Qwen2.5同類模型,特別是在數理、代碼、推理方面表現更為突出。
Qwen3的核心亮點不僅在于參數的提升,更在于其創新的雙重思考模式。面對復雜問題時,模型會進行深入推理,如同老教授般嚴謹;而面對簡單問題時,則會迅速響應,追求效率。用戶還可以根據需求動態控制和切換思考模式,實現了對模型“思考預算”的精細化管理。
Qwen3還具備全球化視野,支持119種語言和方言,真正實現了溝通無界限。其Agent能力也得到顯著增強,支持MCP協議,在工具調用和代碼執行等方面進行了優化,使其更加擅長作為智能助理,與環境交互解決問題。
最重要的是,Qwen3系列強大的模型,包括預訓練基礎模型和后訓練的對話模型,現已全部開源。用戶可以通過Hugging Face、魔搭社區(ModelScope)、Kaggle等主流平臺免費下載并進行商業使用。開發者還可以通過阿里云百煉平臺調用API,并推薦使用SGLang、vLLM等框架進行部署。對于希望在本地體驗的用戶,Ollama、LMStudio、MLX、llama.cpp、KTransformers等工具也已提供支持。

普通用戶則可以通過通義官網或app直接體驗Qwen3,夸克也即將接入,讓更多人能夠輕松享受到AI帶來的便利。
盡管每次新模型的發布都少不了實測環節,但從普通用戶的角度來看,如今的大模型在功能上已相差無幾。各家的差異主要體現在背后的資源調用和成本效益上。因此,我們也僅通過幾個簡單測試來感受Qwen3的實力。
例如,在數字母測試中,大部分我們能免費使用的模型都未能通過。同樣,Qwen3雖然能夠識別出梗圖中的大部分關鍵信息,但也遺漏了最關鍵的一點:東云名乃對自己機器人身份的糾結。
回顧Qwen系列的成長歷程,從2023年的Qwen1.0初出茅廬,到2024年Qwen2.0的鋒芒畢露,再到如今的Qwen3.0的成熟穩健,每一步都充滿了挑戰與不易。在全球AI領域的激烈競爭中,阿里巴巴不僅投入了大量資金,更匯聚了頂尖的技術積累,并堅持開源戰略,贏得了開發者的廣泛尊重。
Qwen系列的發展,是中國AI力量崛起的一個生動寫照。它告訴我們,只要有持續的投入、正確的方向和足夠的韌性,就能在最前沿、競爭最激烈的科技領域不斷取得突破,創造更多驚喜。