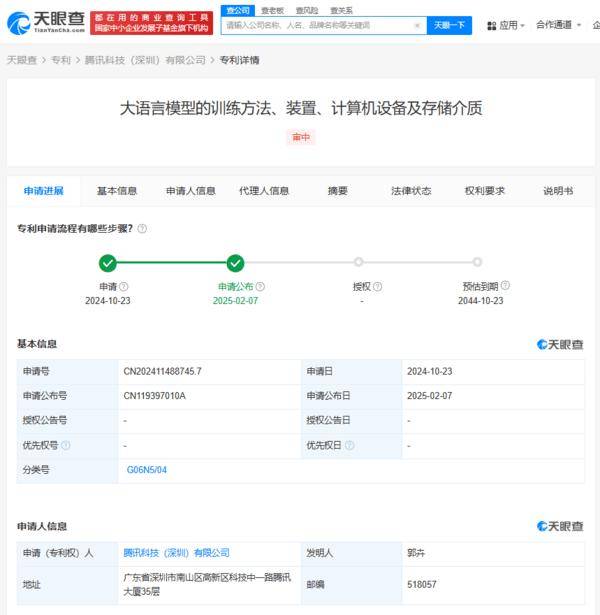
騰訊科技(深圳)有限公司在人工智能領域的又一重大突破于近日揭曉,其申請的“大語言模型訓練新法及配套設施”專利于2月7日正式對外公布。此專利通過引入一種創新的對比學習機制,在大語言模型訓練中巧妙利用多重摘要文本,實現了模型泛化能力與生成準確性的顯著提升,為AI語言處理技術開啟了新的探索路徑。

具體而言,騰訊的新專利創造性地設計了“第一摘要文本”與“第二摘要文本”的概念,兩者在信息量和內容構成上均有所不同,其中第一摘要文本還特別包含了正確與錯誤語句的混合。模型在學習過程中,通過對這兩種摘要的對比分析,能夠更有效地識別并區分正確與錯誤的表達方式,同時顯著降低了因單一數據源而引發的過擬合風險。這一設計不僅極大地豐富了模型的學習維度,還通過動態調整策略,進一步優化了生成結果的準確性和可靠性。
騰訊的這一創新之舉與近年來對比學習在文本摘要領域的廣泛應用趨勢不謀而合。先前的研究已經表明,通過構造正負樣本并調整模型表示空間,對比學習在提升摘要質量、緩解暴露偏差等方面取得了顯著成效。騰訊此次將對比學習框架成功融入大語言模型的訓練中,無疑是對該技術應用邊界的又一次重要拓展。

有業內人士分析指出,騰訊的這項專利通過構建多樣化的摘要文本及高效的對比學習機制,為模型提供了一個更加貼近實際應用場景的學習環境。這對于智能客服、內容生成等需要高精度輸出的領域來說,具有極其重要的實踐意義。該技術還有望加速大模型在實際應用中的落地進程。例如,在短文本對話場景中,騰訊此前已推出的基于混合注意力機制的對話模型專利,若能與這一新的訓練方法相結合,無疑將進一步提升回復的相關性和豐富性,為用戶帶來更加自然流暢的交互體驗。
回顧騰訊近年來在大語言模型領域的布局,從2023年的微調方法專利到此次訓練框架的創新,每一步都彰顯了其在人工智能全鏈條技術領域的深厚積累和前瞻視野。騰訊正以其不懈的努力和持續的創新,推動AI語言處理技術不斷向前發展。